中國網/中國發展門戶網訊 隨著深度學習等技術近年來的突破,人工智包養網價格能(AI)在數學、物理學、化學、生物學、材料學、製藥等自然科學和高技術領域的研究中得到了廣泛應用。例如,DeepMind利用機器學習方法輔助發現數學猜想和定理證明;生物學領域中AlphaFold2已經可以預測超過350 000種人類基因組蛋白質,以及超過100萬個物種的2.14億個蛋白質,幾乎涵蓋了地球上所有已知的蛋白質,解決了困擾結構生物學50年的難題;DeepMind和瑞士等離子體中心合作提出將強化學習用於優化托卡馬克內部的核聚變等離子體控制;華盛頓大學大衛·貝克教授團隊利用AI技術精准地從頭設計出能夠穿過細胞膜的大環多肽分子,創新了口服藥物設計的新思路。這一系列人工智慧技術的成功應用都標誌著以AI for Science(智慧化科研)為核心的第五科研范式已經成為提升科研效率,推進科學發現和科技創新的強大工具,有望帶來人類社會的重大變革。
雖然AI for Science應用領域非常廣泛,但在不同學科領域的應用又有所差別。筆者認為可以將其進一步細分為廣義和狹義的AI for Science。其中,廣義的AI for Science是多種人工智慧技術在科學技術領域的廣泛應用,既包括了自然科學領域的規律和知識發現(如數學猜想的證明、物理規律的發現等),也涵蓋了解決高技術領域的關鍵技術難題(如超短臨天氣預報、托卡馬克控制、生物製藥等)。狹義的AI for Science重點強調自然科學領域的內在規律、知識和結構發現,如發現行星運動的開普勒定律、發現人類基因組蛋白質結構等。與狹義的AI for Science不同,AI用於解決高技術領域的關鍵技術難題主要依賴于發明和創造出新的人造物(artifacts),包括新方案、新方法、新工具和新產品等。AI在高技術領域的應用,由於其應用目的、技術路線等方面和狹義的AI for Science有所不同,筆者認為更適合將其歸類到AI for Technology(技術智慧)的範疇。
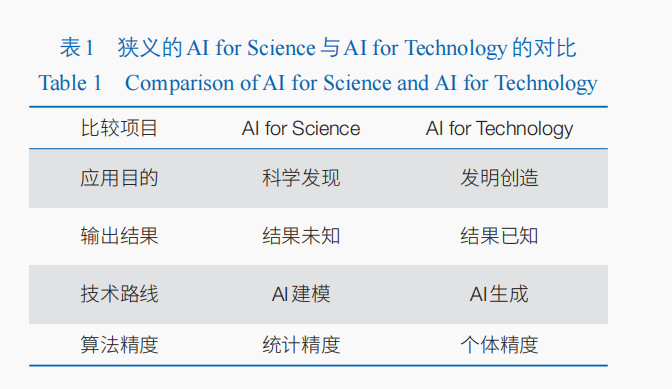
表1總結了狹義的AI for Science和AI for Technology的區別。從應用目的來看,如前所述,AI for Science目的是希望發現自然科學領域人類目前未知的運行機制、機理、規律、結構等;而AI for Technology更強調的是發明創造出滿足特定需求的方案、方法、工具和物品等。以資訊理論來進行類比,AI for Science可以看作是資訊編碼和壓縮的過程,通過AI將大量觀察資料編碼成符號化的規律或知識;AI for Technology包養可以看作是資訊解碼和解壓縮的過程,通過AI將大量滿足需求規範的樣例解碼成人造物的具體設計細節和組成成分。從輸出結果來看,AI for Science本身具有強烈的探索性,其輸出結果是事先未知的;AI for Technology是設計出符合預定義需求規範的人造物,其輸出結果是精確已知的。從技術路線來看,AI for Science主要利用了AI的強大建模能力,實現對大量觀察資料的準確擬合;而AI for Technology則更側重于利用AI的生成能力,以生成滿足需求規範的目標人造物。從演算法精度要求上看,AI for Science追求的是大量資料下統計意義的可接受性,要求輸出的結果可以合理地解釋自然現象(輸入資料),如輸入資料符合特定的統計分佈規律;而AI for Technology強調的是單個個體的精確,要求輸出的個體結果能夠精確地滿足預定義需求規範,如電腦程式自動設計要求輸出的程式碼能夠正確滿足功能和性能規範。從這個角度看,AI for Technology對AI演算法提出了更高的精度要求。
實際上,有關AI for Technology的研究自AI誕生以來就一直備受關注。1969年,諾貝爾經濟學獎及圖靈獎獲得者、人工智慧的奠基人之一赫伯特·西蒙(Herbet Simon)在其《人工科學》(The Sciences of the Artificial)一書中對“自然物”和“人造物”進行了區分,並明確了發明創造滿足人類需求的人造物本身也是門科學(artificial science),可以通過基於電腦程式的通用問題求解系統(general problem solver)來建模人類解決問題的流程,以實現“無人干預的設計”。赫伯特·西蒙和另一位人工智慧的奠基人艾倫·紐威爾(Allen Newell)實現了通用問題求解系統,以自動解決多種不同類型的問題。這本質上是把人類求解問題的過程建模成由機器自動完成的搜索過程。其中的重要組成部分是“生成器—測試”(Generator-Test)的迴圈,即通過生成器產生大量的潛在候選,然後通過測試來確定候選是否滿足需求規範,反復反覆運算直到找到滿足需求的候選。
參考上述流程,可以將AI for Technology建模成為“搜索+驗證”的流程。“搜索+驗證”流程的核心是通過搜索演算法挑選合適的候選,自動驗證所挑選的候選是否滿足需求規範,如果不滿足則需要自動修改和調整以生成新的候選,直到最終的輸出結果滿足需求。近年來,隨著A包養平臺推薦I技術的快速演進,有望同時提升上述搜索和驗證的效率,在擴大應用領域的同時加速整個問題求解的流程。
AI for Technology的科學問題及關鍵挑戰
實現AI for Technology中“搜索+驗證”的迴圈反覆運算,本質上是要解決如何在龐大的高維空間中找到精確滿足複雜約束的最優解問題。對於實際的工程技術問題,其待搜索空間通常包含海量的潛在候選。以圍棋為例,棋盤有361個位置,而每個位置有3種可能,其狀態空間為3361;以蛋白質設計為例,長度為200的氨基酸蛋白,其可能序列有20200種可能;以軟體程式設計為例,長度僅為100條指令的小程式(以廣為使用的SPEC CPU程式為例,實際程式的指令數通常為上百萬條),其狀態空間就已經達到了26 400。這意味著電腦程式需要在龐大高維空間中進行搜索。搜索的目標是要得到滿足人類需求的輸出,而人類需求涉及功能、性能甚至是心理感受等多個維度,這也使得搜索目標的約束異常複雜。以手機的設計為例,除了核心的功能和性能等包養網參數,還涉及需要滿足視覺、觸覺和交互等主觀感受的約束。傳統人工求解方法由於搜索空間龐大同時“搜索+驗證”的反覆運算週期太長,在求解問題時通常僅限於找到滿足約束的解,而人工智慧方法可以極大加速“搜索+驗證”過程,從而找到滿足約束的最優解。
上述科學問題的求解面臨諸多挑戰,主要體現在搜索效率、約束表達和驗證精度上。
挑戰一:如何對龐大的高維空間進行有效剪枝。對於傳統的人工方法而言,由於人腦搜索能力和驗證開銷等限制,必須引入專家領域知識對空間進行大幅裁剪,從而在剪枝後的有限空間中進行搜索和驗證。對於AI技術而言,由於沒有領域知識或難以形式化表達,需要在龐大的高維空間中直接進行搜索。這種方式可以比人類專家考慮更多的潛在候選,從而找到人類專家未知的更優解。但是,由於空間過於龐大,即使是電腦程式也無法做到對整個空間的全遍歷,因此通過AI技術對空間進行精確剪枝,從而在不丟失最優解的前提下將空間壓縮多個數量級至關重要。
挑戰二:如何準確地表達人類模糊二義甚至是不完整的需求規範。很多情況下,人類需求通常採用自然語言來進行描述,天然具有模糊二義性。同時,初始的用戶需求經常具有不完整性,需要通過不斷地反覆運算交互來細化和明確需求規範。例如,赫伯特西蒙就以艦艇設計為例說明了設計約束的複雜性,需要指揮官、作戰人員、設計人員和各組件設計負責人等的不斷交互反覆運算才能轉變成為方便電腦求解的“結構良好問題”(well-structured problem)。近來熱門的大語言模型由於建模了大量人類常識和經驗,有望在從需求描述到問題形式化定義的轉換過程中提供有效支撐。
挑戰三:如何保證輸出個體精確滿足複雜約束。如前所述,AI for Technology要求輸出的單個人造物能夠精確地滿足預定義的需求規範,即在單個樣本上就要達到絕對正確。這與主流AI演算法(如神經網路)主要強調統計意義上的精確性(對一張圖片的識別錯誤影響不大)是矛盾的。即便是大語言模型在很多場景下提高了輸出結果的精度,也無法在理論上提供精度的保證,導致在很多關鍵場景下仍然無法應用。因此需要通過演算法理論的創新,能夠在理論上保證輸出精度或給出演算法的理論下界,使得用戶對輸出結果是否滿足需求規範有明確判斷。
AI for Technology的應用實踐:CPU晶片的全自動設計
筆者將AI for Technology的基本思想應用到了資訊技術的核心物質載體——中央處理器(CPU)的設計和實現中,首次成功實現了在無人干預情況下由機器全自動設計出一款32位CPU——“啟蒙1號”。與傳統流程一般需要2—3年才能設計出一款工業級的CPU晶片不同,筆者團隊僅在5小時內就完成了“啟蒙1號”的全部前端設計,極大地提高CPU晶片的設計效率,有望變革傳統的晶片設計流程。
與傳統基於人工的CPU設計流程從需求規範出發,並且主要由工程師完成架構設計、邏輯設計、功能驗證等流程不同,筆者團隊提出的CPU設計方法本質上是以驗證為中心的設計方法:在驗證計畫指導下從隨機電路出發,由機器全自動完成包括驗證、調試和修復的反復反覆運算直到獲得滿足設計需求的目標電路(圖1)。其中,自動驗證主要是檢查結果是否滿足需求並自動生成新的驗證用例,自動調試是根據出錯的結果搜索並定位出錯的電路邏輯,自動修復則是在出錯的電路邏輯基礎上進一步搜索正確的電路邏輯。因此,自動調試和自動修復都可以看作是搜索的過程,與自動驗證一起組成的完整流程遵循前面所介紹AI for Technology的“搜索+驗證”核心流程。
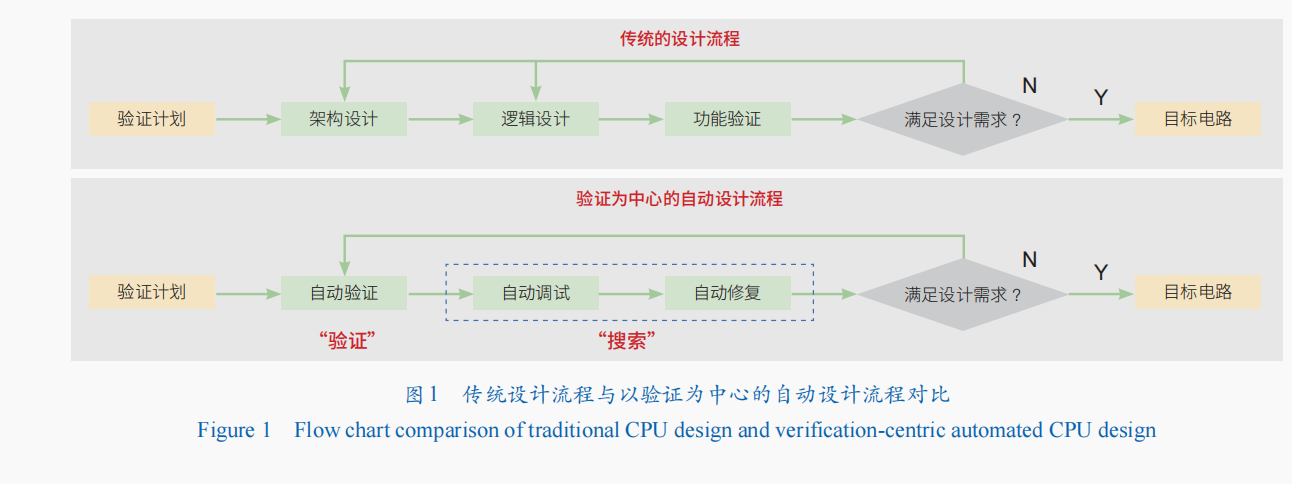
為了保證驗證的精度,筆者提出了基於二元猜測圖(Binary Speculation Diagram,BSD)的設計方法。BSD方法是建立在傳統的二元決策圖(Binary Decision Diagram,BDD)的基礎上,通過將傳統BDD中的確定性子圖替換成BSD中通過蒙特卡洛採樣來確定的猜測節點。該方法天然具有良好的可解釋性和“單調性”(即演算法每次對電路的修改都能夠比之前的設計更接近正確的設計),從而解決前述“自動調試”和“自動修復”的問題。具體而言,首先,BDD演算法的樹狀結構能夠很快搜索確定節點所對應的邏輯函數與外部輸入輸出之間的關係,從而自動定位錯誤以解決自動調試的問題;其次,隨著BDD的不斷搜索展開,其所對應的邏輯函數理論上可以不斷逼近原始函數,從而解決自動修復的問題。
CPU全自動設計是A包養I for Technology的典型應用,即通過AI技術來發明創造出CPU設計。實際上筆者發現自動設計出來的CPU不僅滿足了由指令集架構(ISA)所預定義的功能需求,同時機器學習過程中甚至自主地發現了包含控制器和運算器等在內的馮諾依曼架構。對於機器而言,由於事先並沒有關於馮諾依曼架構的任何預定義知識,這在一定程度上也同時呈現出了AI for Science用於“科學發現”和“結果未知”的特徵。
AI for Technology的未來展望
為了讓AI for Technology能夠在更多的高技術領域得到深度應用,未來可以從“搜索+驗證”的核心流程入手,考慮如何進一步提高搜索和驗證的效率,在加速創新流程的同時具備更強的創造能力,最終期望超過人類的發明創造水準。具體可以分別從人工智慧範式的交叉融合、與第三科研範式的交叉融合等方面進行探索研究。
從搜索的角度看,其核心目的是提高搜索演算法本身的效率,使其能夠以更快速度逼近最優解。梯度下降法在神經網路等領域取得了巨大的成功,但是很多實際問題本身並不可微或者可微近似會帶來極大的精度損失,導致難以直接應用梯度下降法。這種情況下應考慮多種人工智慧範式的交叉融合。例如,AlphaGo中蒙特卡洛樹搜索結合了以深度學習為代表的連接主義和以強化學習為代表的行為主義。這標誌著連接主義和行為主義已經在實際應用中呈現出了交叉融合的趨勢。前面所介紹的CPU設計例子主要是基於以BDD為代表的符號主義來進行搜索。未來通過符號主義、連接主義和行為主義的深度交叉融合,有望大幅度提升搜索效率,從而在更大的搜索空間中找到更優的結果。
從驗證的角度看,對輸出結果是否滿足需求規範進行判斷通常要在真實環境中進行實驗驗證。例如,新材料的設計需要通過實際實驗來對其力學特性和耐久特性等進行充分測試。這勢必會造成驗證的資源投入和時間開銷太大。為加速驗證收斂,可以借助電腦類比來構建回應模型,通過與回應模型的交互來判斷是否滿足需求規範。仍以CPU設計為例,實踐中無法對每種可能的處理器設計都通過實際流片來進行驗證,而是通過構建準確的模擬器來判斷是否滿足需求。因此,未來通過與基於電腦類比的第三科研範式進行深入融合,構建起高效且準確的回應模型,有望進一步加速驗證乃至整個創新流程。
(作者:陳雲霽,中國科學院計算技術研究所 中國科學院大學電腦科學與技術學院;郭崎,中國科學院計算技術研究所。《中國科學院院刊》供稿)